This is a visual guide explaining how AI chatbots such as ChatGPT, Claude, and Gemini work. I aim to explain the core concepts behind these systems, avoiding both unnecessary details and the cryptic analogies that often obscure important terms (by sharing different analogies 😎).
This post will cover the following topics. No prior knowledge is required - However I assume you've used a chatbot before and are familiar with basic geometry.
- Large Language Models (LLMs) - the main technology behind AI assistants
- What are they?
- How are they created?
- How are they used to build ChatGPT-like systems?
Large Language Models
The backbone of AI assistants are language models. What exactly are they? It's simple: language models just predict the next word of a text sequence.

Well, not really. It's more precise to say that a language model assigns probabilities to every potential next word in the sequence, or what we call a probability distribution. In fact, this is why they are called "language models" - they model the language by predicting which words are likely to follow others.
So how exactly is this useful? The most straightforward application of a language model in its raw form can be seen in your smartphone. Most modern smartphones have a feature where your keyboard suggests potential next words as you type. In this case, it makes sense to suggest the most likely words that could follow your text.
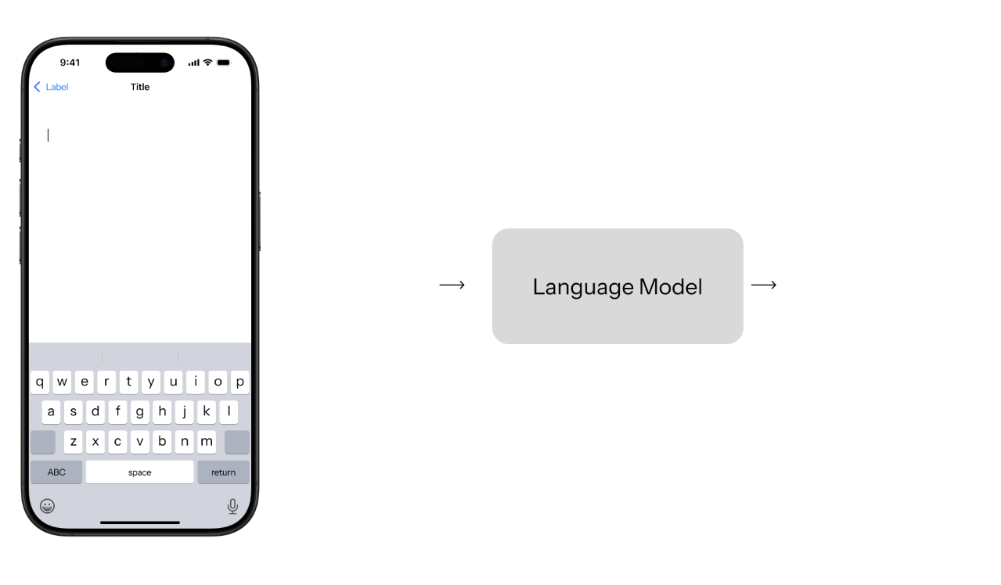
But how do we create such models?
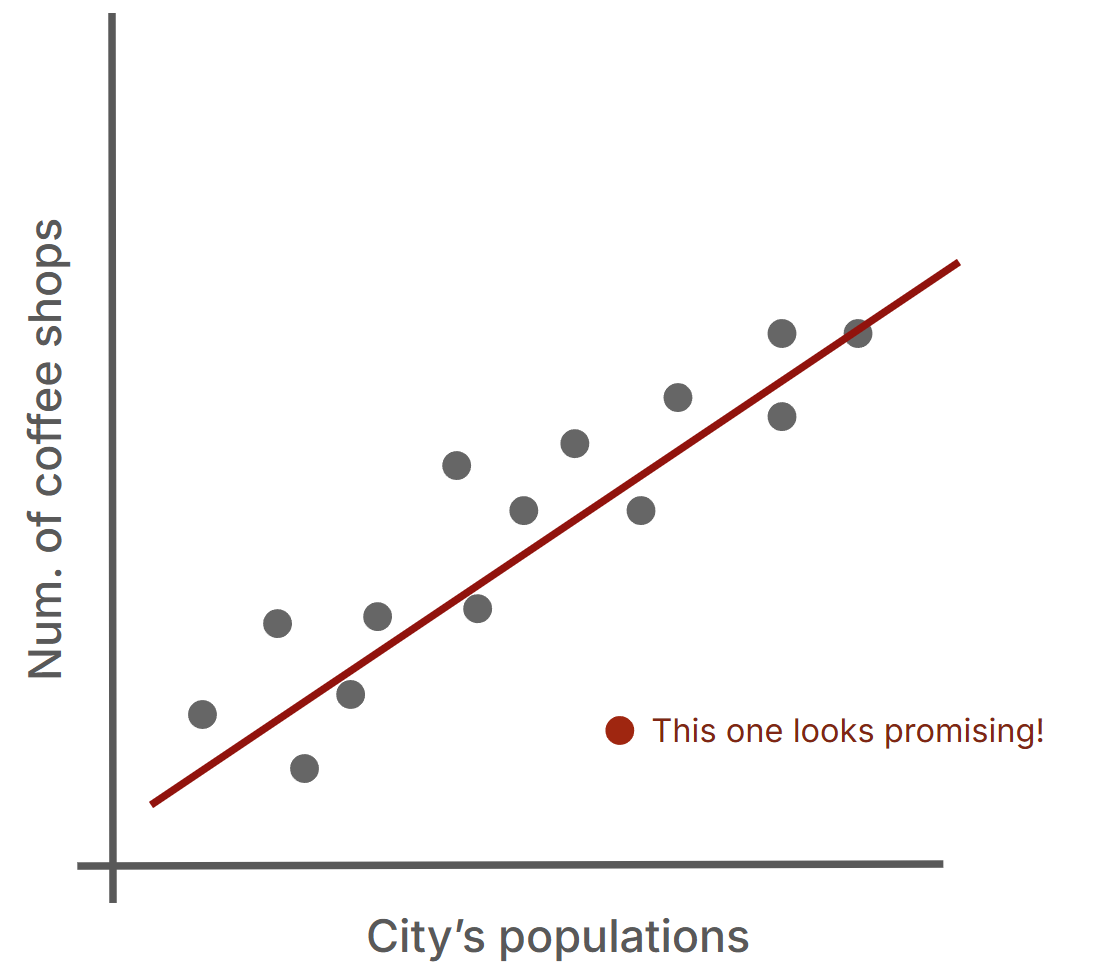
Let's start with a simple example. Imagine we want to help entrepreneurs decide where to open new coffee shops. We could look at different cities, counting how many coffee shops they have compared to their population. If we plot this data as dots on a chart, we might notice a pattern - larger cities tend to have more coffee shops.
To make this pattern more useful, we can try to draw a straight line that best captures the relationship. This line becomes our simple "model" - it tells us roughly how many coffee shops we'd expect in a city of a given size. What's particularly interesting are the cities that fall far below this line - these might be promising locations for new coffee shops since they have fewer shops than we'd expect for their size.
When looking at these dots, we could try to draw a line by hand. But imagine if we had data from thousands of cities, or if we wanted to update our line every week as new data comes in. Drawing by hand would become impractical. That's why we use a mathematical formula to describe the line: $$ y = mx + c $$ This formula lets a computer draw the line for us automatically - we just need to find the right values for $m$ and $c$. You can try adjusting these values yourself to see how they change the line:
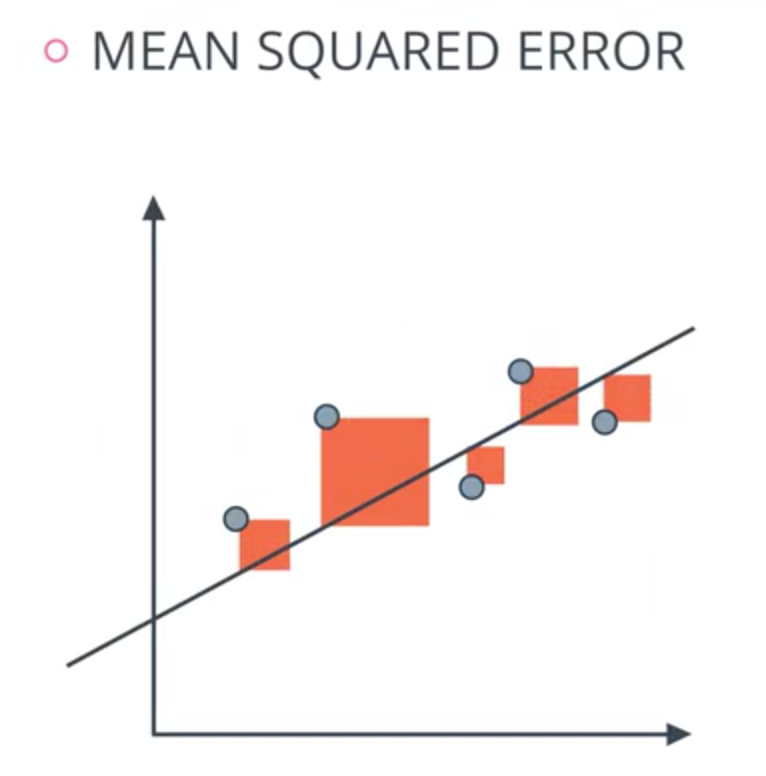
How does an ideal line look like? Usually, we want the line to be as close as possible to all our dots. To see how well a line fits, click here to show the distances between the dots and the line. While you could try to minimize these distances by hand, we can actually find the perfect values for $m$ and $c$ mathematically, letting a computer do the work quickly and precisely 1.
Now, language models work in a similar way, but instead of a formula that predicts coffee shop numbers, they use a formula that outputs probability distribution of next words. And instead of finding the best values for just two parameters ($m$ and $c$), they use much more complex formulas with hundreds of billions (≥ 100,000,000,000) parameters to adjust. That's why we call them large language models.
When you hear about "training" AI systems or making them "learn", it's exactly like our line example - we're just finding the right numbers to make the mathematical formula work properly. The only difference is the massive scale - while we could adjust our line manually, with language models we need lots of compute power to find the right values for all these parameters.
Training large language models
Just like we needed data from many cities to find the trend line, a language model also needs examples to learn from. What are the dots in this case? Instead of each dot being a city with its coffee shops, each dot is a piece of text and what word comes next. For example: "Thank you very" and the next word "much".
When we first create a language model, its parameters are set randomly, so its predictions make no sense at all - it might think words like "banana" or "spaceship" are just as likely to follow "Thank you very" as the word "much". Similar to how we tried to minimize the distances between our dots and the line, we try to minimize how wrong these predictions are. We show the model what actually came next - in this case "much" - and adjust its parameters slightly. By repeatedly showing the model examples like this, we gradually tune its parameters so it learns to predict sensible continuations instead of random words.

So how many examples do we need to train a good language model? We're talking about hundreds of billions of words from webpages, books, articles, and other sources. Processing this much data and at this scale requires extremely powerful computers, which is why training these models costs a lot of money 💸💸💸.
The result of this process is that now the model produces the probabilities of the next words that are aligned with what the model saw in the training data. It has learnt language patterns, it has memorized lots of facts, different writing styles, opinions, or multiple languages. However, if there is one thing I want you to remember, it is that all the model is actually doing and was taught to do is to tell us what possible words could come up next in a text. No fact-checking, no internet searching, no "human-thinking" is done inside the model.
How do we turn a language model into a chatbot?
To generate a longer text with a language model, we start with some input text and let the model predict one word at a time. Each predicted word gets added to our text, and we ask for another prediction. Repeat this process, and you'll get a complete sentence or even a paragraph.

If you've ever played with your phone's keyboard suggestions, tapping only the suggested words, you know you can create some funny but mostly nonsensical sentences. Similarly, a freshly trained language model can only do simple text completion. Type "Hey," and it might suggest "what's up?" - but it won't respond with "Hi! How can I help you today?" like modern AI assistants do.
To get from basic text completion to helpful conversations, we need an extra step. We continue training the model (you've might heard finetuning the model), but this time with very specific data - examples of conversations. We show it many examples of exchanges between users and helpful assistants. These conversations include everything from simple questions and answers to complex problems with detailed solutions. It's like showing the model "This is how you should respond when someone asks for help."
What makes this work is that the model treats the entire conversation - both user questions and assistant responses - as one continuous text sequence. But for this to work effectively, we need a way to help the model (and us) to distinguish between different parts of this sequence. Think of it like a movie script - we need to clearly mark who's speaking:
- Fabienne: Whose motorcycle is this?
- Butch: It's a chopper, baby.
- Fabienne: Whose chopper is this?
- Butch: It's Zed's.
- Fabienne: Who's Zed?
- Butch: Zed's dead, baby. Zed's dead.
In practice, we use simple markers - roughly something like USER: and ASSISTANT: to structure our training conversations. We also add special signals that model learns to tell us when to stop generating the assistant's response, similar to saying "over" in radio communications. We can then parse out the assistant's responses using those special markers - though at its core, the model is still just predicting what words should come next in that sequence.
- USER: Hi!
- ASSISTANT: Hello, how can I help you?[STOP_SIGNAL]
- USER: What's the world's largest ocean?
- ASSISTANT: *Dwight Schrute mechanical noises* Pacific![STOP_SIGNAL]
It's important to understand that ChatGPT, Claude, and similar applications are actually two separate pieces: the language model (LLM) that generates text, and the chat interface (the app) that helps you interact with it. Here's what happens behind the scenes when you use these apps:
- When you type "Hi!", the app adds USER: before your message.
- It then adds ASSISTANT: after your message.
- The app sends this formatted text to the language model, which generates the response word by word.
- When the model generates the [STOP_SIGNAL], the app knows the response is complete and displays it to you.

And that's pretty much it. The extra abilities - like searching the web or using external tools - are just clever “behind-the-scenes” integrations on the app-level that feed relevant results back to the model. Handling images or audio, on the other hand, often involves specialized systems or separate models. Yet at its core, the "writing" AI is still driven by that same foundational principle: predicting what comes next in a conversation.
What's next?
In my (hypothetical) next blog post, I'll explore how LLM APIs work under the hood. While avoiding complex mathematics, I'll explain the key architectural details that shape both the capabilities and limitations of AI assistants. This should be useful for developers and anyone curious about how these systems work in more details.
Topics that I might cover:
- Tokens, vocabulary and context length
- Sampling parameters
- Roles (system, user, assistant, ...?)
- Function calling / Tool use
- ... your suggestions?
Acknowledgments and further reading (watching)
For those familiar with AI, you may know Jay Alammar's excellent blog which clearly inspired this post. I recommend this post for deeper learning:
- A Visual and Interactive Guide to the Basics of Neural Networks
- I later discovered Jay had already used the line-fitting analogy in his post.
- His guide offers detailed and interactive insights into the learning process.
And if you prefer videos, you can watch these:
- 3Blue1Brown's Large Language Models explained briefly, or
- 1 hour long Andrej Karpathy's Intro to Large Language Models
Footnotes
- If we use slightly different distances than visualized - the squared errors, we are able to derive two "simple" formulas for ideal $m$ and $c$ beforehand:
- where $n$ is the number of data points, $\sum$ represents a summation of $x_i$/$y_i$-coordinates of the given points. You can read more here, but beware, statistical terminology and equations can get really nasty 🤮.
$$m = \frac{n\sum(x_i y_i) - \sum x_i \sum y_i}{n\sum(x_i^2) - (\sum x_i)^2}$$ $$c = \frac{\sum y_i - m\sum x_i}{n}$$
{kind=link}